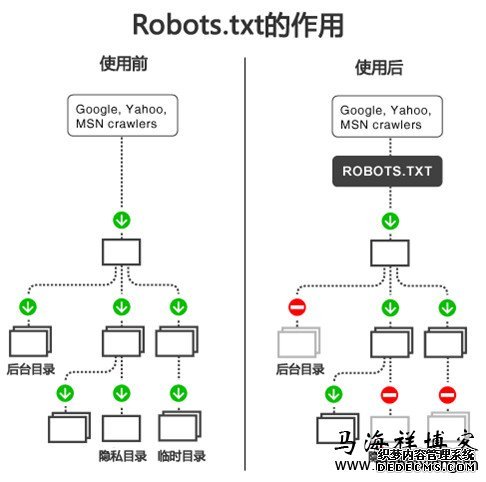
当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
一、什么是Robots协议
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(RobotsExclusionProtocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
robots是一个协议,而不是一个命令。robots.txt文件是一个文本文件,是放置在网站根目录下,使用任何一个常见的文本编辑器,就可以创建和编辑它。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件,其主要的作用就是告诉蜘蛛程序在服务器上什么文件是可以被查看的。
如果将网站视为一个房间,robots.txt就是主人在房间门口悬挂的“请勿打扰”或“欢迎进入”的提示牌。这个文件告诉来访的搜索引擎哪些房间可以进入和参观,哪些房间因为存放贵重物品,或可能涉及住户及访客的隐私而不对搜索引擎开放。但robots.txt不是命令,也不是防火墙,如同守门人无法阻止窃贼等恶意闯入者。
所以,马海祥建议各位站长仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用robots.txt文件,如果您希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。
二、Robots协议的原则
Robots协议是国际互联网界通行的道德规范,基于以下原则建立:
1、搜索技术应服务于人类,同时尊重信息提供者的意愿,并维护其隐私权;
2、网站有义务保护其使用者的个人信息和隐私不被侵犯。

可能有的同学要问了,我怎么知道爬虫的User-agent是什么?这里提供了一个简单的列表:爬虫列表
当然,你还可以查相关搜索引擎的资料得到官方的数据,比如说google爬虫列表,百度爬虫列表
(2)、Disallow
Disallow行列出的是要拦截的网页,以正斜线(/)开头,可以列出特定的网址或模式。
要屏蔽整个网站,使用正斜线即可,如下所示:
马海祥博客解释:意思也就是禁止百度蜘蛛和Google蜘蛛抓取所有文章
2、robots.txt的高级写法
首先声明:高级玩法不是所有引擎的爬虫都支持,一般来说,作为搜索引擎技术领导者的谷歌支持的最好。
(1)、allow
如果需要屏蔽seo1-seo100,但是不屏蔽seo50,那我们该怎么办呢?
方案1:
聪明的你一定能发现其中的规律,对吧?谁管的越细就听谁的。
(2)、sitemap
前面说过爬虫会通过网页内部的链接发现新的网页,但是如果没有连接指向的网页怎么办?或者用户输入条件生成的动态网页怎么办?能否让网站管理员通知搜索引擎他们网站上有哪些可供抓取的网页?这就是sitemap。
最简单的Sitepmap形式就是XML文件,外贸网站营销在其中列出网站中的网址以及关于每个网址的其他数据(上次更新的时间、更改的频率以及相对于网站上其他网址的重要程度等等),利用这些信息搜索引擎可以更加智能地抓取网站内容。
新的问题来了,爬虫怎么知道这个网站有没有提供sitemap文件,或者说网站管理员生成了sitemap(可能是多个文件),爬虫怎么知道放在哪里呢?
由于robots.txt的位置是固定的,于是大家就想到了把sitemap的位置信息放在robots.txt里,这就成为robots.txt里的新成员了,比如:
考虑到一个网站的网页众多,sitemap人工维护不太靠谱,对此,马海祥建议你可以使用google提供了工具可以自动生成sitemap。
(3)、metatag
其实严格来说这部分内容不属于robots.txt,不过也算非常相关,我也不知道放哪里合适,暂且放到这里吧。
robots.txt的初衷是为了让网站管理员管理可以出现在搜索引擎里的网站内容。但是,即使使用robots.txt文件让爬虫无法抓取这些内容,搜索引擎也可以通过其他方式找到这些网页并将它添加到索引中。
例如,其他网站仍可能链接到该网站,因此,网页网址及其他公开的信息(如指向相关网站的链接中的定位文字或开放式目录管理系统中的标题)有可能会出现在引擎的搜索结果中,如果想彻底对搜索引擎隐身那咋整呢?马海祥给你的答案是:元标记,即metatag。
比如要完全阻止一个网页的内容列在搜索引擎索引中(即使有其他网站链接到此网页),可使用noindex元标记。robots协议文件的写法及语法属性解释-南昌网站优化只要搜索引擎查看该网页,便会看到noindex元标记并阻止该网页显示在索引中,这里注意noindex元标记提供的是一种逐页控制对网站的访问的方式。
比如:要防止所有搜索引擎将网站中的网页编入索引,那你就可以在网页的头部代码部分添加:
这里的name取值可以设置为某个搜索引擎的User-agent从而指定屏蔽某一个搜索引擎。
除了noindex外,还有其他元标记,比如说nofollow,禁止爬虫从此页面中跟踪链接。这里马海祥再提一句:noindex和nofollow在HTML4.01规范里有描述,但是其他tag的在不同引擎支持到什么程度各不相同,还请读者自行查阅各个引擎的说明文档。
(4)、Crawl-delay
除了控制哪些可以抓哪些不能抓之外,robots.txt还可以用来控制爬虫抓取的速率。如何做到的呢?通过设置爬虫在两次抓取之间等待的秒数。
表示本次抓取后下一次抓取前需要等待5秒。
马海祥博客提醒大家一点:google已经不支持这种方式了,不过在webmastertools里提供了一个功能可以更直观的控制抓取速率。
这里插一句题外话,几年前马海祥记得曾经有一段时间robots.txt还支持复杂的参数:Visit-time,只有在visit-time指定的时间段里,爬虫才可以访问;Request-rate:用来限制URL的读取频率,用于控制不同的时间段采用不同的抓取速率。
后来估计支持的人太少,就渐渐的废掉了,有兴趣的博友可以自行研究一下,马海祥了解到的是目前google和baidu都已经不支持这个规则了,其他小的引擎公司貌似从来都没有支持过。
四、Robots协议中的语法属性解释
Robots协议用来告知搜索引擎哪些页面能被抓取,哪些页面不能被抓取;可以屏蔽一些网站中比较大的文件,海外网站推广如图片,音乐,视频等,节省服务器带宽;也可以屏蔽站点的一些死链接,方便搜索引擎抓取网站内容;再或者是设置网站地图连接,方便引导蜘蛛爬取页面。
User-agent:这里的代表的所有的搜索引擎种类,是一个通配符。
Disallow:/admin/这里定义是禁止爬寻admin目录下面的目录。
Disallow:/mahaixiang/.htm禁止访问/mahaixiang/目录下的所有以".htm"为后缀的URL(包含子目录)。
Disallow:/?禁止访问网站中所有包含问号(?)的网址。
Disallow:/.jpg$禁止抓取网页所有的.jpg格式的图片。
Disallow:/mahaixiang/abc.html禁止爬取ab文件夹下面的adc.html文件。
Allow:/mahaixiang/这里定义是允许爬寻mahaixiang目录下面的目录。
Allow:/mahaixiang这里定义是允许爬寻mahaixiang的整个目录。
Allow:.htm$仅允许访问以".htm"为后缀的URL。
Allow:.gif$允许抓取网页和gif格式图片。
Sitemap:/sitemap.html告诉爬虫这个页面是网站地图。
举例:
马海祥博客解释:意思就是有禁止所有搜索引擎来抓网站中所有包含问号(?)的网址和seo目录下的.htm文章。同时,对etao完全屏蔽。
五、Robots协议中的其它语法属性
1、Robot-version:用来指定robot协议的版本号
例子:Robot-version:Version2.0
2、Crawl-delay:雅虎YST一个特定的扩展名,可以通过它对我们的抓取程序设定一个较低的抓取请求频率。
您可以加入Crawl-delay:xx指示,其中,“XX”是指在crawler程序两次进入站点时,以秒为单位的最低延时。
3、Crawl-delay:定义抓取延迟
例子:Crawl-delay:/mahaixiang/
4、Visit-time:只有在visit-time指定的时间段里,robot才可以访问指定的URL,否则不可访问。
例子:Visit-time:0100-1300#允许在凌晨1:00到13:00访问
5、Request-rate:用来限制URL的读取频率
例子:Request-rate:40/1m0100-0759在1:00到07:59之间,以每分钟40次的频率进行访问。
Request-rate:12/1m0800-1300在8:00到13:00之间,以每分钟12次的频率进行访问。
马海祥博客点评:
Robots协议是网站出于安全和隐私考虑,防止搜索引擎抓取敏感信息而设置的,搜索引擎的原理是通过一种爬虫spider程序,自动搜集互联网上的网页并获取相关信息。
而鉴于网络安全与隐私的考虑,每个网站都会设置自己的Robots协议,来明示搜索引擎,哪些内容是愿意和允许被搜索引擎收录的,哪些则不允许,搜索引擎则会按照Robots协议给予的权限进行抓取。
Robots协议代表了一种契约精神,互联网企业只有遵守这一规则,才能保证网站及用户的隐私数据不被侵犯,违背Robots协议将带来巨大安全隐忧。
本文为马海祥博客原创文章,如想转载,请注明原文网址摘自于,注明出处;否则,禁止转载;谢谢配合!